Retrieval Debt: The Technical Debt Your Agent Is Paying Right Now
Retrieval Debt is how much context an agent must load to safely understand, change, and verify a single unit of behavior. Lower is better. Always.


I started thinking about a simple question: will software design principles still matter when AI agents do most of the coding?
The answer I kept coming back to was: more than ever. Not because the principles changed. Because the reader did.
Your agent indexes your codebase once. But every session it reasons from scratch. No memory of last week’s decisions. No context about why that tradeoff was made. Just retrieval and a best guess.
Token costs spike. Wrong files get edited. You end up guiding your agent through your own codebase like onboarding a new hire who cannot ask questions and never remembers the answers.
Most teams think this is an AI problem. It is a design problem.
Agents Inherit Your Design Decisions
Software design principles were never about aesthetics. They existed to manage ambiguity for whoever changes the code next. The audience was always the next reader who needs to understand this and modify it safely.
That reader is now an agent. And agents suffer from ambiguity more than humans do, not less.
A human encountering unclear code slows down. They hesitate. They ask questions. An agent does the opposite. It makes a confident decision and moves forward.
Ambiguity doesn’t create caution in agents. It creates confident mistakes at scale.
Good design amplifies good agent output. Bad design amplifies bad agent output. The principles didn’t become irrelevant. They became more expensive to ignore.
Three Constraints That Make Violations Expensive
Agents operate under three hard constraints humans never had, and understanding these is why the rest of this post matters.
Context window means agents can only reason about what they retrieve. Scattered logic means partial picture, wrong assumptions, missed files. What a human fills with intuition and experience, an agent either retrieves correctly or gets wrong confidently. There is no middle ground.
Cost means every token loaded is a line item on your bill. Poor design is no longer just slow. A messy codebase costs significantly more to operate on than a clean one. Bad architecture now has a direct, measurable infrastructure cost.
Accuracy is the dangerous one. A human who encounters ambiguous code slows down, double checks, asks questions. An agent encountering the same ambiguity does not hesitate. It makes a confident decision and moves forward. A human who misses something feels unsure. An agent that misses something believes it is done.
Every principle that helped humans manage complexity maps directly onto these three constraints.
Every Principle, Through the Agent Lens
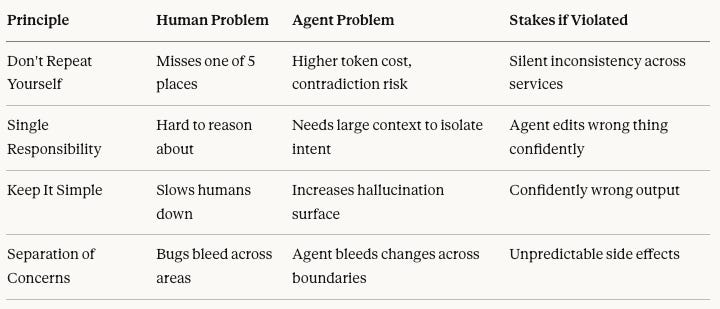
The problems didn’t change. The cost of getting them wrong did.
This Is Not Theoretical
Before going further, here is why this pattern shows up consistently across tools and research.
Cursor ships a 500 line file limit recommendation specifically because large files degrade agent retrieval quality. ¹ LLM research consistently documents accuracy loss on information buried in long contexts, what researchers call the lost in the middle problem. ² And in January 2026 Cursor shipped dynamic context discovery, moving away from static context loading toward pulling only what the agent needs on demand. Their A/B tests showed a 46.9% token reduction just from tighter context loading. ³
Three independent signals pointing at the same thing. Retrievability dominates cost, speed, and correctness.
They are building tooling to compensate for bad codebases. Low Retrieval Debt makes that compensation unnecessary. The teams that win won’t have the best agent prompts. They will have codebases that are cheap to understand, cheap to modify, and hard to misunderstand.
Naming Is Now Architecture
Agents don’t remember your codebase. They find it through semantic search. Your repository is indexed as vector embeddings and the agent retrieves what looks relevant to the query.
Poor naming isn’t a style issue. It is a retrieval failure.
# Agent searching "discount logic" will miss this
def compute_final_value(u, amt, fl=False):
if u.tier == 2:
amt = amt * 0.9
# Agent finds this immediately
def apply_user_discount(user, order_amount: float, is_flash_sale: bool = False) -> float:
premium_discount = 0.10
Same logic. One surfaces. One doesn’t. The agent that misses the first version doesn’t raise a hand. It reimplements somewhere else and moves on confidently.
A function with single responsibility averages 20 to 50 lines. A god class doing six things averages 400 or more. An agent loading the god class to change one behavior loads 8 to 20 times more tokens than necessary. That is not a style problem. That is an infrastructure cost.
Naming conventions are no longer bikeshedding. They are part of your agent infrastructure.
Retrieval Debt: The Metric That Matters
Retrieval Debt is how much context an agent must load to safely understand, change, and verify a single unit of behavior. Lower is better. Always.
This applies to your static codebase, core domain logic, data models, API contracts. Ephemeral generated code and throwaway scripts are a different conversation. But the foundation your agents build everything else on top of will always need these principles, and in an agentic world it needs them more rigorously than ever.
Discount logic scattered across three services means three retrievals, three formula structures, three edits, and a silent inconsistency the agent believes it already fixed. The same logic centralized means one retrieval, one edit, one test.
# High Retrieval Debt
# cart_service.py
if user.is_premium:
total *= 0.9
# order_service.py
if user.is_premium:
price = price * 0.9
# invoice_service.py
discount = 0.1 if user.is_premium else 0
final = amount - (amount * discount)
# Low Retrieval Debt
# pricing/discounts.py
PREMIUM_DISCOUNT = 0.10
def apply_user_discount(user, amount: float) -> float:
if user.is_premium:
return amount * (1 - PREMIUM_DISCOUNT)
return amount
A human missing one location creates a bug. An agent missing one location creates a silent production incident it is confident never happened.
What This Means for Your Team
Agents have no domain understanding, no memory of past tradeoffs, no intuition about why your system looks the way it does. Their guess is often structurally plausible and contextually wrong.
Senior engineers become more valuable, not less. Their role shifts from writing code to shaping the context agents operate in, boundaries, names, abstractions, architectural intent. They nudge agents toward the right design by making the problem clear enough that the agent cannot go too far wrong.
For product and engineering leaders who don’t live in the code: ask your team one question. How many files does an agent need to read to safely change this feature? If they don’t know, or if the answer is more than three, you have a Retrieval Debt conversation worth having before your next planning cycle.
If your best engineers are shepherding agents through a messy codebase instead of making architectural calls, your structure is the bottleneck. That is Retrieval Debt showing up as a people cost.
How to Reduce Retrieval Debt This Week
The 2-3 file rule. If a safe change requires more than 2-3 files, you have a problem worth fixing now.
The single retrieval test. Could an agent find the right place with one semantic search? If not, your naming or boundaries are wrong.
The edit surface check. Count how many places change for one business rule update. More than two is Retrieval Debt.
The Bottom Line
Your codebase is no longer just a communication medium between engineers. It is a knowledge base your agents query under cost and accuracy constraints, thousands of times a day.
Agent debt is the new technical debt. Retrieval Debt is how you measure it.
Start with your most changed modules. Count the retrievals needed to make a safe change. Drive that number down.
Most teams are accumulating this without noticing. The ones who design against it now will compound quietly while everyone else wonders why their agent productivity hit a ceiling.
¹ Cursor, Working with Context, docs.cursor.com/en/guides/working-with-context ² Lost in the Middle, Stanford NLP Research, 2023 ³ Cursor, Dynamic Context Discovery, January 2026. cursor.com/blog/dynamic-context-discovery