Context Tiering for Claude Code: The CLAUDE.md Setup That Survives Long Sessions

TL;DR: Claude Code has 3 context tiers. Put rules in the wrong tier and Claude “forgets.” This is the Context Tiering setup that took me from a 470-line CLAUDE.md and constant reminders to 94 lines and ~99% first-try eval pass.
I had a rule in CLAUDE.md saying “every PR touching ORM models MUST include a migration.” Claude followed it for 20 turns. By turn 40, it was happily adding model fields without migrations. Bold warnings, checklists, repetition: none of it worked.
The fix wasn’t a better prompt. It was moving the rule out of CLAUDE.md entirely.
Claude Code doesn’t forget. It compresses. And if your rules live in the wrong tier, they get compressed first, which is why your 470-line CLAUDE.md feels like it works for 20 turns and then quietly stops.
3 months running Claude Code in production, mostly on Opus, building real systems for real users. Started at 470 lines of CLAUDE.md. Ended at 94 lines plus a layered system of rules, skills, and guidelines. First-try eval pass rate went from ~70% to ~99%. I used to write “don’t forget the migration” or “add eval cases” in almost every prompt. Now I write it zero times. The system handles it.
The model didn’t get smarter. The context architecture did.
The Mistake Everyone Makes
You start by dumping everything into CLAUDE.md: architecture, coding standards, workflows, security rules, eval framework, design patterns. Then Claude:
Forgets your migration checklist on long conversations
Doesn’t follow coding standards 50 messages deep
Lets subagents invent their own rules
I wrote the same rule three times hoping repetition would help. It didn’t. Repetition isn’t reinforcement. Placement is.
You’re treating CLAUDE.md like a knowledge base. It’s not. It’s permanent context, loaded every single turn, never compressed. A 470-line file eats ~2000 tokens per message and Claude’s attention to any individual rule drops as the file grows past ~200 lines.
The Mental Model: Context Tiering
Claude Code has three context tiers, each with a different lifetime:
markdown
PERMANENT (every turn, never compressed)
CLAUDE.md keep TINY
.claude/rules/* (glob-scoped) auto-loaded invariants
Memory index cross-session recall
ON DEMAND (loaded when read, compressed over time)
guidelines files reference docs
skill bodies workflow instructions
TEMPORARY (compressed first when context fills)
conversation, file reads, search resultsCritical rules go where they’ll never be compressed. Reference knowledge loads only when needed. Everything else is temporary, and that’s fine.
Get this wrong and Claude “forgets.” Get this right and Claude behaves like a senior engineer who actually reads the docs.
The Decision Framework (the most reusable thing in this post)
For any instruction, ask in order:
markdown
Q1: If Claude violates this, does something BREAK?
YES -> RULE (.claude/rules/)
Q2: Is this triggered by a specific task with ordered steps?
YES -> SKILL (.claude/skills/)
Q3: Is this reference knowledge Claude looks up while coding?
YES -> GUIDELINE (<topic>-guidelines.md)
Q4: Does Claude need this every single turn to understand the project?
YES -> CLAUDE.md (keep it SHORT)
Q5: Is this an isolated, parallelizable task that would bloat main context?
YES -> SUBAGENT (fresh instance, brief it like a new hire)
NO to all -> don't add it.Examples:
“Never import from customers/ in platform code” → breaks multi-tenancy → Rule
“When building a skill: add tracing, write evals, register, sync to Langfuse” → 7 ordered steps with a clear trigger → Skill
“PascalCase classes, snake_case functions” → reference, no trigger → Guideline
“B2B SaaS for insurance document processing” → needed every turn for context → CLAUDE.md
“Audit all Dockerfiles and report inconsistencies” → isolated, read-heavy, parallelizable → Subagent
If you remember nothing else from this post, remember this framework.
The Five File Types
1. CLAUDE.md (~100 lines): identity and navigation. Project overview, essential commands, folder structure, pointers to other docs. Nothing else. Past 100 lines, Claude’s attention to any single rule starts dropping.
2. Rules files (~30 lines, in .claude/rules/): hard constraints, glob-scoped, never compressed.
markdown
.claude/rules/no-customer-imports.md
globs: src/myapp/**
Platform code must NEVER import from customers/. Breaks multi-tenancy.This completely solved my migration problem. The 48-line Alembic section that Claude forgot in CLAUDE.md became a 12-line rule that fires every time Claude touches models.py. Haven’t missed a migration since.
Glob scope is the lever: globs: ** = permanent everywhere (use sparingly). globs: **/Dockerfile = nearly free.
3. Guidelines files (~250 lines): coding standards, design patterns. Loaded on demand, compressed over time. Fine, because rules catch the critical stuff.
Split by concern. My original coding-guidelines.md was 727 lines. Every time Claude needed to check a naming convention, it loaded 727 lines covering Python, architecture, skills, migrations, and security. ~3000 tokens for a 20-line answer. I split it into 3 files. Now “fix a Python bug” loads 215 lines. “Design a feature” loads 91. “Build a skill” loads 145.
4. Skills (~200 lines, in .claude/skills/): workflows with a trigger and ordered steps. The ~50-token description is always in context so Claude auto-detects when to fire. The body loads only when invoked. Test: can you describe the trigger in one sentence? Are there 3+ ordered steps? Yes to both = skill.
5. Per-directory CLAUDE.md (~50 lines): only what’s unique to that module. I audited my project and found 74 CLAUDE.md files that were nothing but auto-generated activity logs with zero instructions. Deleted all of them. Kept 31 that had real documentation. Empty per-directory files are noise tax on every session.
Subagents: The Insight That Changes Everything
Subagents are fresh Claude instances. They inherit your CLAUDE.md and rules. They inherit zero conversation history.
If a constraint only exists in your chat, it doesn’t exist for the subagent.
BAD: “Based on our earlier research, fix the bug”
GOOD: “In src/myapp/skills/extract_core.py line 280,
extract_from_classified() fails when classified images
contain duplicate tags. Fix: deduplicate by image path
before the extraction loop.”
I use subagents heavily. When I needed to audit all my Dockerfiles, CLAUDE.md files, and coding guidelines, I launched 4 in parallel. Each explored a different area and came back with findings. Main context stayed clean. If I’d done it inline, file reads alone would have eaten half my window.
The 70% → 99% Trick: Triple Reinforcement
“Always add evals” written in CLAUDE.md alone works ~70% of the time. To reach ~99%:
markdown
Layer 1: Skill DESCRIPTION (always in context)
Auto-detects "I'm building a skill" and triggers /eval-design
Layer 2: CLAUDE.md INSTRUCTION
"Every change to LLM code MUST use /eval-design"
Layer 3: Rule FILE (auto-loaded on skills/** edits)
"Every skill needs tracing + evals + tests + registry"This is how I solved the eval problem. Our pipeline can silently degrade accuracy on any prompt change. Just writing the rule wasn’t enough. Claude would build a skill, write tests, and forget evals. With three layers, compliance is ~99%. If any one fails, the other two catch it.
Build Rules Reactively
Start with zero. Add them when things break:
markdown
Week 1: Claude commits a .env file -> no-secrets rule
Week 2: Claude skips a migration -> migration-required rule
Week 3: Skill ships without evals -> skill-completeness rule
Week 4: Platform imports customer code -> isolation rule
All 7 of my rules came from real incidents. The platform isolation rule? Claude imported a customer-specific config parser into the platform module. Broke the second customer’s integration. The dependency pinning rule? Claude added litellm>=1.0 and the next build pulled a breaking version. Each rule paid for itself within a week.
Don’t pre-create 20 hypothetical rules. They bloat permanent context and dilute attention across the rules that actually matter.
Cheat Sheet
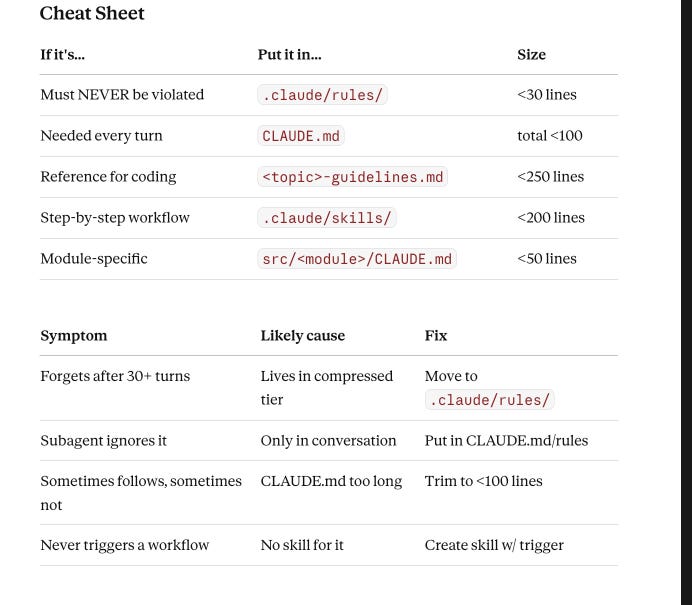
The Real Lesson - Feedback Loop
One of the key for this setup is feedback loop, every time I merge a PR a hook runs which collects all the learning from the session and update the setup following the guidelines - your setup evolves with your codebase.
Writing code with an LLM is becoming commodity. Anyone can spin up Claude Code in 5 minutes. The leverage isn’t in the model anymore. It’s in the context architecture and feedback loop you build around it
Context is the moat. The rules, skills, guidelines, and glob-scoped invariants are the asset. They compound. They make every future session better. They turn a flaky genius into a predictable senior engineer.
If your AI workflow feels magical-but-fragile, you don’t need a better model. You need a better context architecture.
This refactor will take one afternoon. It saves that much every single day.