Coding Agents Need Software Factories

Most engineering teams are making the same mistake with coding agents - confusing faster code generation with faster software delivery.
The bottleneck was never just writing code. It was turning code into software the organization can trust and deploy.
A real software change often touches frontend, APIs, database migrations, infra, rollout flags, integration tests, monitoring, and deployment plans. It has to fit the architecture, respect service contracts, work across repos, pass the right tests, survive rollout, and be trusted in production.
This is where most coding agent workflows still break.
The agent writes the code, but the developer still carries the engineering system context - architecture, repo ownership, service contracts, verification paths, rollout risks, and memory of what failed last time.
I have seen agents open 10,000-line PRs and changes with multiple consumers. At that point, no one can confidently say whether the change works, what it breaks, or whether it still follows the architecture. PRs start queuing up. Reviews take days or weeks. Verification becomes the bottleneck.
The real gap is between generating code and delivering software the organization can trust.
This is why coding agents need software factories.
A Software Factory is a control plane around coding agents. It preserves context, coordinates work, verifies outcomes, learns from every run, and improves itself.
A Software Factory needs three things around coding agents:
A brain that holds the engineering context - repos, architecture, contracts, infra, ownership, decisions, failures, and verification paths.
A sandbox where the factory can bring up the system, run checks, validate integrations, and prove the change works.
A learning loop that turns failed runs and repeated manual work into better workflows, skills, and agents.
Without this, agents produce changes that look right locally but fail at integration points. Developers still carry the context, risk, and memory. Every session starts from zero.
Example: Cross-Repo Feature Development
Imagine a feature touches three repositories owned by three teams.
The code changes are easy.
The problem is knowing what changes first, what depends on what, which contract can break, which tests need to run, and what has to be deployed in what order.
Today, a developer opens Codex or Claude in each repo and asks for the local change.
But the real coordination still happens in the developer’s head.
This API is changing here.
This frontend needs to consume it.
This worker needs to emit a new event. Current infra setup needs to be considered.
This test needs to run after all three changes land.
This rollout should happen after the backend is deployed.
The agents are writing code. The developer is still doing the delivery work - coordinating branches, tests, PRs, dependencies, and hidden integration risks.
In a Software Factory model, you ask once:
Build this feature across the affected repos.
The factory runs a simple loop:
Spec → Build → Verify → Learn → Evolve
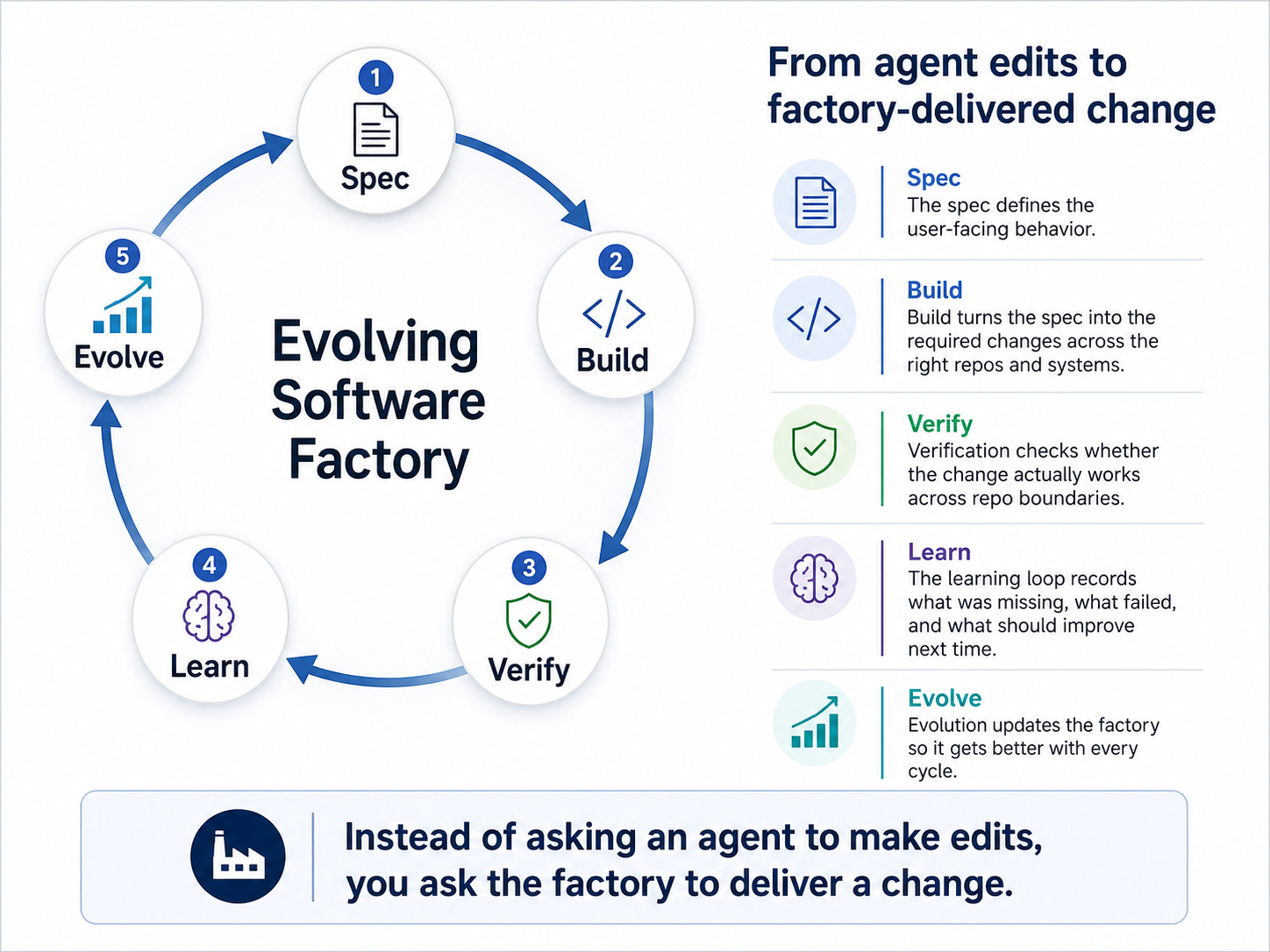
Spec Agent brainstorms and defines the outcome.
Build Agents brainstorms and turns the spec into coordinated changes across repos, contracts, data flows, and rollout paths and implement them.
Verification Agent proves whether the change actually works.
Learning Agent captures what was missing, what failed, and what needs to improve next time.
Evolve Agnet updates the factory so the next run is better.
Human coordinates and brainstorm with these agents to ship the feature.
I ran this on a real change spanning four services, including frontend. The architect agent identified the repositories that needed to change, came up with high level design. It delegated the work to lead agents, who broke the request into steps, designed the implementation, and made the changes.
Then a verifier agent spun up the services, tested them, validated the frontend-backend integration, captured screenshots of the working flow using Playwright MCP, and produced a PR summary reviewers could trust.
The system did not just generate code. It coordinated the change, verified the outcome, and produced evidence for review.
Instead of asking an agent to make a code change, you ask the factory to deliver a change.
The Factory Is Not Just For Code Changes
Once the factory has the engineering brain, it is not limited to feature work.
It can diagnose production, cost, reliability, security, and compliance issues because all of them are connected to code, infra, data flows, ownership, policies, and deployment history.
For example, I asked the factory for the top three cost drivers from last month and the reason behind each spike.
The main agent connected to AWS, pulled last month’s cost data, identified the top three services driving spend, checked metrics and infra configuration, correlated the spike with code changes and deployment history, and was able to pinpoint the repo and module where the increase came from.
A normal coding agent cannot do that by only reading the codebase.
A shallow answer would be:
Your database costs are high.
A useful answer is:
Cost increased after this deployment by 28%.
The spike came from this worker because a filter moved from the database layer to application code.
The affected repos are
backend-apiandreporting-worker.Verification should include query plan comparison, worker runtime tests, and a cost estimate after replaying the workload.
The useful part is that it can trace the issue back properly - which deployment caused the spike, which service changed, which repo owns it, and what needs to be tested before the fix goes out.
The same factory that helps ship features can also help debug cost, reliability, security, and compliance issues.
The foundation is the same - connected context, verification, and learning loop.
The Brain Is The Engineering Context Layer
The brain gives the factory its engineering memory.
It cannot be a folder of docs or one long prompt. It needs to behave like a knowledge graph: repos, services, contracts, workflows, infra, tests, owners, decisions, failures, and skills connected to each other.
This is important because engineering knowledge is not flat.
A code change depends on architecture.
Architecture depends on infra.
Infra affects cost, reliability, and security.
Verification depends on service contracts.
Future work depends on decisions made today.
The knowledge graph helps the factory understand these connections: which repo owns an API, which service consumes an event, which migration affects a workflow, which test proves a contract still works, which past failure needs to be considered, and which agent or skill fits the work.
If agents do not have access to that connected system context, they will keep producing changes that pass locally and fail in production
Once it knows the affected repos, contracts, workflows, and verification paths, it decides which agents are involved, what each agent does, which repos need changes, what order the work happens in, and how the final change comes together.
Every meaningful change gets checked against the architecture, contracts, ownership boundaries, operational patterns, and previous decisions.
For simple work, the factory keeps the path lightweight -one agent, one repo, one clear verification step.
For larger work, it coordinates multiple agents across frontend, backend, infra, tests, and documentation.
Developers should not be the coordination layer. They should not have to remember which repo changed, which branch depends on what, which test proves the contract, or which dependency can break the release.
The factory coordinates the run.
Developers should guide the system when judgment is needed, not manually coordinate every repo, branch, test, and rollout step.
The Sandbox Verifies The Work
The sandbox is where the factory verifies work.
The system brings up all the services, runs tests, checks contracts, validates integration paths, and proves whether the change works.
This does not mean every change goes through a heavy process.
A good factory has two lanes.
Fast lane handles small fixes: one repo, low risk, obvious verification.
Full lane handles work with real coordination risk - cross-repo features, API changes, infra changes, data migrations, cost work, and anything that affects rollout confidence.
The factory chooses the lane, runs the right checks, and produces evidence.
The developer reviews the evidence and makes the final release call.
How The Factory Improves
Each run should make the next one easier.
After every run, the factory asks:
What context was missing?
Which workflow was too manual?
Which verification step failed too late?
Which repeated step should become a skill?
Which area needs a specialized agent?
Which decision needs to be recorded for future runs?
After each run, feedback is incorporated back into the system.
If a cross-repo change fails because one service emits created_at but another expects createdAt, the factory does not just fix the bug. It records the contract mismatch, updates the verification workflow, and checks that boundary before future PRs.
If local setup fails because seed data is missing, the factory should update the setup skill so future runs start from a working sandbox.
For example, if the authentication flow requires a dummy user and password, the factory should seed those credentials during setup and update the local setup instructions. The next time an agent runs the workflow, it should not have to rediscover the same missing dependency again.
If frontend-heavy work repeatedly needs the same review pattern, the factory turns that pattern into a reusable frontend verification skill, or proposes and create a specialized frontend lead agent.
For example, if an agent needs a skill that does not exist, such as python-best-practices, it can propose it, create it, and use it before writing code.
The factory is version-controlled so that skills, workflows, verification rules, setup instructions, architecture decisions, and lessons from failed runs are all reviewable and teams can collaborate.
Developers and agents work together and improve the factory together, which compounds the system.
The Shift
The unit of work changes from “make this edit” to “ship this outcome safely.”
You no longer ask an agent to make the code change. You ask the factory to take an outcome and carry it through spec, build, verification, and learning.
Claude, Codex, and Cursor are not the factory.
They are the workers inside it.
The factory is the control plane around them: one shared engineering brain for every kind of engineering work, where agents coordinate, the sandbox proves changes, and the system improves with every run.
A prompt gives you output.
A factory gives you a change with tests, screenshots, affected repos, rollout order, and a trail reviewers can trust.
Build your own factory using prinevo.ai.