Building a Software Factory: From Prompts to Compounding Systems

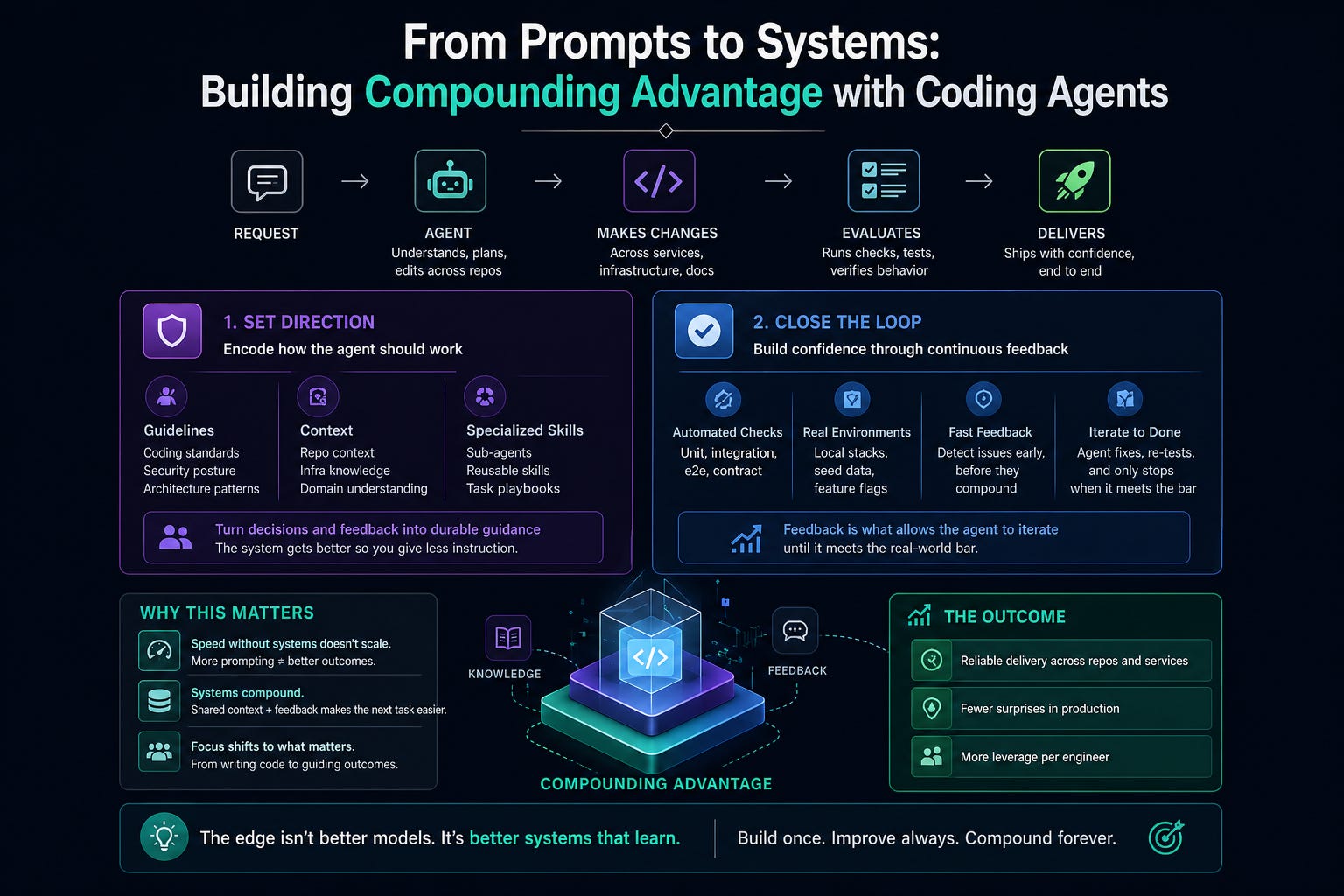
As coding agents get better, the bottleneck shifts. Code generation is commoditizing. Planning what to build, defining guardrails and context for how to build it, and verifying the change become the work.
Here’s a metric most teams aren’t tracking: changes to your agent setup (CLAUDE.md, skills, sub-agents) vs changes to your codebase. Does your agent need less instruction over time? That’s the only signal proving your setup is compounding.
Most teams aren’t measuring this. Engineers are prompting on top of the codebase, shipping fast, feeling productive. But the system isn’t getting smarter. Everyone is prompting the same things over and over.
That’s individual speedup with zero org-level compounding. Your team may feel faster, but the system itself isn’t improving.
Compounding starts when repeated prompts become shared system behavior. Before the two shifts that make it happen, a frame worth naming.
A compounding setup has two layers.
The brain holds context, policy, and decisions. CLAUDE.md, skills, sub-agents, architecture rules, security posture. This is where org knowledge lives.
The sandbox is where the agent executes and verifies. Local services, seed data, integration tests, the ability to bring the system up and watch it break.
Most teams have neither. They have a chat window and a codebase. That’s why prompting feels productive but never compounds. There’s nowhere for the learning to land, and nowhere for the agent to test what it built.
The two shifts below are how you build each layer.
1. Invest in the verification layer (this is the sandbox)
How fast can you verify what the agent shipped? Unit tests, integration tests, e2e automation, the ability to bring services up locally with seed data.
This mattered when humans wrote code. It’s 10x more important now.
Last week an agent shipped a multi-repo change where one service emitted created_at and the consumer expected createdAt. Code looked clean in both repos. Tests passed in isolation. An integration test caught it in the sandbox before it hit higher environments.
Most failures aren’t generation failures. They’re verification failures at integration boundaries.
A real feedback loop moves the human up the stack. The agent completes the task, brings services up locally, tests, iterates when it fails, and keeps going until acceptance criteria are met.
2. Turn prompts into policy (this is the brain)
When an agent misbehaves, don’t just re-prompt and move on. Pass the feedback into the system. Update CLAUDE.md, agent.md, sub-agent skills.
Re-prompting is individual work. Updating the context and guardrail layer is org work.
The team’s job becomes managing how the agent builds: security posture, architecture patterns, migration strategy. Every mistake the agent makes is input for the guardrail layer.
Once both layers are in place, you can build a compounding software factory above the codebase: an agent with context across repos and infra, taking a request, making multi-repo changes, bringing services up, testing, and shipping end to end.
Code generation is no longer the hard part. It’s managing shared context across repos and having a verification layer that lets the agent iterate until it converges.
The created_at vs createdAt story is the small version. At scale it’s schema drift, contract mismatches, and infra assumptions that only show up when services talk.
Teams that treat coding agents as individual productivity tools will get speed.
Teams that treat them as compounding software factories will get leverage.
This is Part 1. Next: how to actually build the brain and sandbox layers. Verification loops, feedback systems, shared context, and what has to be in place for agents to compound.